
Today we’re going to see how supervized learning model can help a machine to name color from its RGB value. The programming language used for the solution is Python.
As you probably know, a color image is made up of pixels. Each pixel has a triplet value representing the values of red green and blue (RGB).
Examples:
RGB value red=250, green=128, blue=114, give:
RGB value red=0, green=255, blue=255, give:
Our human eye allows us to perceive and identify colors, and to say that the color seen above corresponds to pink or blue, but how the machine should know this with simple RGB value?
When a human sees a color that is close to pure red, he will deduce that this color is red (I apologize for the colorblindness). Giving this behavior to a machine is simple: if I give him an RGB value (unnamed color), the machine can compare this color to colors already named, by finding the nearest color. It can deduce from this that the name of the unnamed color is the same that the name of the nearest color that it has found.
Gathering data from sources
The first step before building the model is gathering data from sources. To the day I write this article CSS support 147 colors names, we can find the list of colors name on this website: https://www.rapidtables.com/web/css/css-color.html. On this website, each color is represented by his name and his RGB value.
I created a small Python script that allows me to retrieve this data from the website. This article does not deal with Web scrapping, for more information about this, I invite you to read the official documentation of Beautifulsoup (the library that I use to collect data from the web page). You will find however the script I used to collect data, and you can also download the generated CSV file here.
1 | from bs4 import BeautifulSoup |
Load and visualize data
Named colors are now in the colors.csv file. pandas python library allows loading data from CSV to data frame with the read_csv function.
1 | import pandas as pd |
Display the 5 fist line of the data frame with df.head(5):
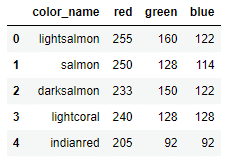
Each color has a name and RGB value with a unique ID.
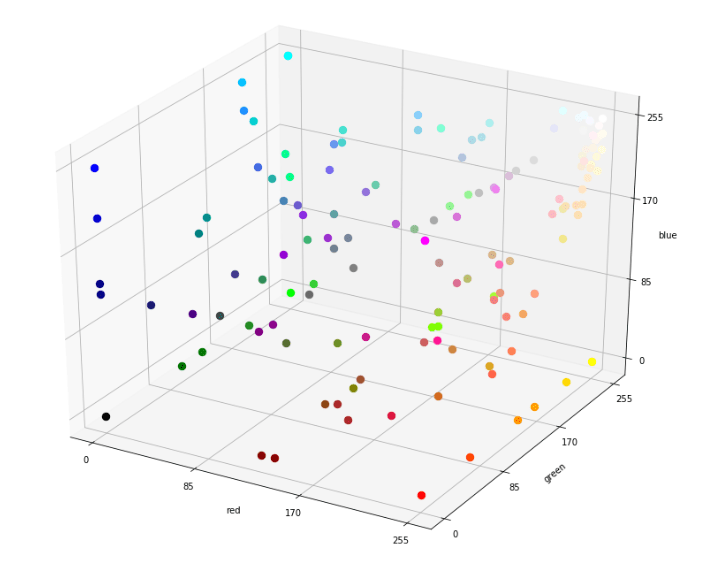
An RGB value can be seen as a point (between 0 and 255) in a 3-dimensional space. To see this, we can use the Matplotlib data visualization library to represented on a 3D scatter plot each point of the data frame with his real color and with RGB value as axis.
1 | from mpl_toolkits.mplot3d import Axes3D |
Choose the most appropriate model
The last step before building a model is to choose which is the most appropriate to solve the problem. The goal is to give a name for an unnamed color finding the closest named color, what we can see as points in 3-dimensional space. We can also see each named colors as a unique category. Classification is the problem of identifying to which of a set categories a new observation belongs. For this problem, a category is a named color and unnamed colors are the new observations.
The k-nearest neighbors (k-NN) algorithm perfectly match with the problem (find the closest point). k-NN is a supervised algorithm that stores all the available cases and classifies the new data or case based on a similarity measure. It is mostly used to classifies a data point based on how its neighbors are classified.
In the classification phase, $k$ is a user-defined constant, and an unlabeled vector (a query or test point) is classified by assigning the label which is most frequent among the $k$ training samples nearest to that query point. If $k=1$, then the object is simply assigned to the class of that single nearest neighbor.
Train the model
The Python scikit-learn library implements the k-nearest neighbors for classification via the sklearn.neighbors.KNeighborsClassifier class. There are many parameters in this class but the only one that will interest us today is n_neighbors which represents the $k$ parameter and that we will set to 1.
It is also necessary to retrieve the RGB values (X) from the data frame defined above, and the ID (y) of each color that will be the class to predict. These values will represent the training set.
1 | from sklearn.neighbors import KNeighborsClassifier |
Use the model to name color
Now that the model has been trained it is possible to name new colors. I have created a function that takes as a parameter a triplet that represents a RGB value, and returns the name of that color. Simply call the predict method of the model which will take the tuple as a parameter, and return an ID from the data frame. Finally, we can ask the data frame to provide us with the name associated with the ID.
1 | def name_color(rgb): |
Examples:
name_color((18, 47, 133)) give midnightbluename_color((102, 158, 30)) give olivedrabname_color((221, 145, 35)) give goldenrodConclusion
We have seen how supervised learning can help a machine to name colors from its RGB value. To make the model more accurate you can add new named colors to the training set. You can also have fun via this link http://www.darkart.com/cgi-bin/colors.cgi giving names to randomly generated colors. Soon I will be writing an article on unsupervised learning and color. In the meantime, thank you for reading this article, see you later!



